

最近在进行数据的过滤,就需要保证数据库入库的数据为唯一的,因为业务的需求,并不能直接直接对数据库做唯一的限制,因此,在数据完成入库后,要对唯一性再次做判断。
首先做实验,这个记录是一定有重复的,看看情况如何文章源自陈学虎-https://chenxuehu.com/article/2018/10/7330.html
SELECT meta_key, COUNT( meta_key ) FROM youhui_postmeta GROUP BY meta_key HAVING COUNT( meta_key ) > 1
结果文章源自陈学虎-https://chenxuehu.com/article/2018/10/7330.html
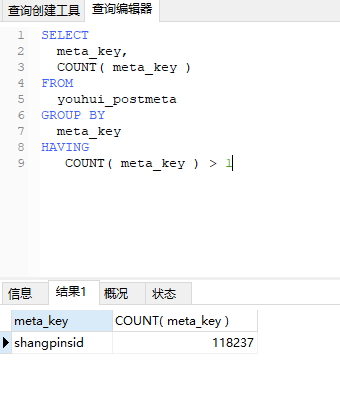 文章源自陈学虎-https://chenxuehu.com/article/2018/10/7330.html
文章源自陈学虎-https://chenxuehu.com/article/2018/10/7330.html
从结果可以判定,有重复值,那接下来,验证没有重复的情况文章源自陈学虎-https://chenxuehu.com/article/2018/10/7330.html
SELECT meta_value, COUNT( meta_value ) FROM youhui_postmeta GROUP BY meta_value HAVING COUNT( meta_value ) > 1
结果文章源自陈学虎-https://chenxuehu.com/article/2018/10/7330.html
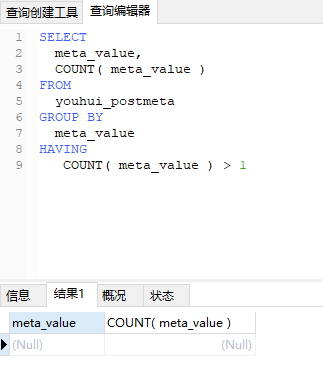 文章源自陈学虎-https://chenxuehu.com/article/2018/10/7330.html
文章源自陈学虎-https://chenxuehu.com/article/2018/10/7330.html
文章源自陈学虎-https://chenxuehu.com/article/2018/10/7330.html
所以验证是没有问题的,因此SQL就是这么验证列是否存在重复值的。文章源自陈学虎-https://chenxuehu.com/article/2018/10/7330.html
文章源自陈学虎-https://chenxuehu.com/article/2018/10/7330.html 文章源自陈学虎-https://chenxuehu.com/article/2018/10/7330.html








评论